How to use Azure Archive Blob Storage for long-term data retention

Long-term data retention is a hard problem to solve for multiple reasons. First, it is a real challenge to find a cost-effective storage medium that is convenient to maintain. Secondly, it is not easy to keep track of large amounts of data over long time periods. Lastly, the need to recall data from long-term retention can turn out to be a costly and arduous exercise.
However, this is all changing with the latest advancements in cloud computing.
Meet Microsoft Azure Archive Blob Storage
Microsoft Azure has a storage tier explicitly designed for long-term data retention: Azure Archive Blob Storage.
Before we explore how you can use the Archive tier in Azure, it is essential to understand that cold storage in the cloud is something offered by many cloud providers. We think Microsoft has leapfrogged similar competitive offerings with the Archive tier for two main reasons:
- Granularity of control – Microsoft’s API design for archiving in the cloud supports comprehensive data management. The ability to query, access, and manage data is becoming more critical than ever before with compliance requirements such as the EU’s General Data Protection Regulation (GDPR). Unlike other cloud providers’ approaches to deep archiving that force an arbitrary containerization of your data, with Microsoft Azure, you can manage and access individual objects within the Archive tier.
- Superior storage economics – Microsoft’s storage prices for the Archive tier are the most attractive on the market today.
Cold Archiving in the Cloud: How It Works
With the introduction of blob-level tiering control, your Azure Blob storage accounts now support a mix of tiers wherein individual items can be either Hot, Cool, or Archive.
Furthermore, you can change the tier at any time. Thus, placing content in and out of a cold storage state is conveniently done in-place with no management overhead.
Can Azure-based Cloud Archiving Replace Tape?
Advocates for tape media will call out that cloud storage does not compete with tape’s low storage prices.
Let’s face it: Provided that you do not have legal discovery and GDPR requests, tape is going to be the most cost-effective medium to store data in the long term.
However, ask any experienced eDiscovery lawyer, and they will tell you that tape is extremely expensive in a litigation scenario.
Archiving unstructured data in the cloud is revolutionizing long-term data management because it delivers a cost model comparable to tape economics, but unlike tape, the cloud is an intelligent secondary storage environment that is agile.
For example, if you run Veritas Alta™ SaaS Protection on Microsoft Azure for long-term retention, you have the following advantages over tape:
- Convenience – Cloud storage uses native disk format with synchronous storage redundancy and erasure coding for durability. Even in the Archive tier, your cold data storage does not become dark data. Granular blob-level controls support data management, file analysis, user access, and the GDPR.
- Discovery efficiency – Deep archiving in the cloud preserves your ability to look up and even search the data on demand, with access to the information that is precise and always ready. Organizations that might face audits, investigations, or litigation should weigh the costs of discovery against tape compared to the cloud’s intelligent archive model.
- Built-in data protection without lock-in – Data on tape is considered safe when it is offline. However, then you must worry about the physical management of the media, and offsite warehousing vendors can lock you in. Cloud storage is, by default, redundant and self-healing with options for geo-redundancy and shadow copy that can provide a backup to protect against malicious insider attacks, all under control and ownership in the cloud that is yours.
- No infrastructure management overheads – With cloud storage, there is no hardware lifecycle to manage. The IT team no longer worries about maintaining a tape library infrastructure and refreshing the tape hardware every seven to 10 years, for instance.
- Security and global reach – All data in the Archive tier is automatically encrypted at rest using 256-bit AES encryption. The Archive tier is available in multiple Azure regions worldwide, and its availability is still expanding.
How Does Veritas Alta™ SaaS Protection Integrate with Azure Archive Storage?
It is often said that the downside of cloud storage is that it lacks rich data management functions such as search, legal hold, WORM retention policies, and access control. Moreover, things like native deduplication and compression, file analytics, data classification, and activity auditing are also lacking.
We must keep in mind that cold storage options in the cloud are provided at the infrastructure-as-a-service (IaaS) level. The primary cloud provider’s IaaS provides excellent economies-of-scale for disk-based storage pricing that is comparable to tape, and because of things like synchronous storage redundancy and erasure coding, you do not worry about data durability and hardware refreshes.
However, to satisfy an organization’s need for cloud data management, search, and access, you need more than just the IaaS layer; You also need the Software-as-a-Service (SaaS) layer to be present and tightly integrated with the underlying IaaS.
Let us take a closer look at how Veritas Alta SaaS Protection, a SaaS archive solution built on Azure, integrates with the Archive tier to deliver the best of both worlds.
Storage Tiering to the Cloud
The first challenge, of course, is how you can seed data to the cloud quickly.
Veritas Alta SaaS Protection includes software that connects to a variety of data sources. Your data from SaaS applications is copied by Veritas Alta SaaS Protection and then stored on the cloud tier specified by your tiering and retention policies. Additionally, the solution can be used to archive on-premises file system data and likely be the data repository that will benefit the most by having a release valve for long-term retention storage.
Using the policy controls in Veritas Alta SaaS Protection’s Connector Service, you can target multiple shares and directories at any level with individual policies.
If you wish to archive older data but have no disruption to users or applications, Veritas Alta SaaS Protection supports policy-based cloud tiering. The stubbing method is based on policies that you define, so you can selectively leave pointers in the file system so that users and applications can initiate recall of data from the cloud archive.
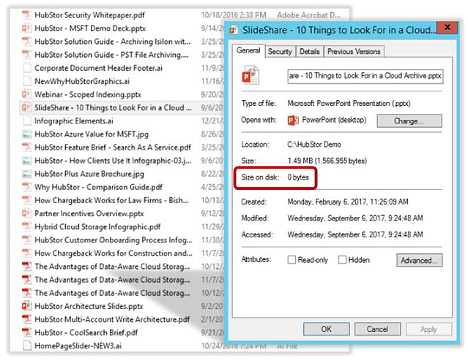
Figure 1: Stub file as it appears on a user’s desktop.
Data residing in the Hot or Cool tier is instantly retrievable. However, as we will later explore, items in the cold storage tier in the cloud do not recall immediately. Instead, they have a rehydration lag before the blobs are ready. Thus, you may find it ideal to remove stubs on-premises that point to items in Azure’s Archive tier since the recall request will return an error. Using HubStor’s policy controls, you can phase out stubs according to your rules for moving data to the Archive tier.
However, you do have the option of leaving stubs in your on-premises file servers that point to items in cold storage. In this case, a request on a stub will initiate the object to be rehydrated from the Archive tier, at which point the stub will again work to recall the item as expected.
In-cloud Storage Tiering
In the cloud archive, Veritas Alta SaaS Protection’s object storage layer includes analytics and a granular policy engine that makes it easy to visualize and manage the distribution of content across the Hot, Cool, and Archive tiers.
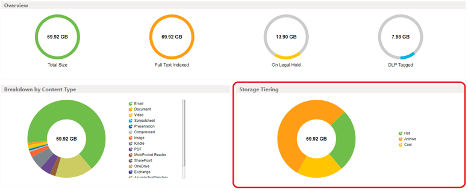
Figure 2: Veritas Alta SaaS Protection storage analytics.
HubStor enables IT administrators to manage storage tiering in Azure with rules that target data based on folder, last accessed, type, data owner, user or group access rights, size, DLP tags, and custom fields.
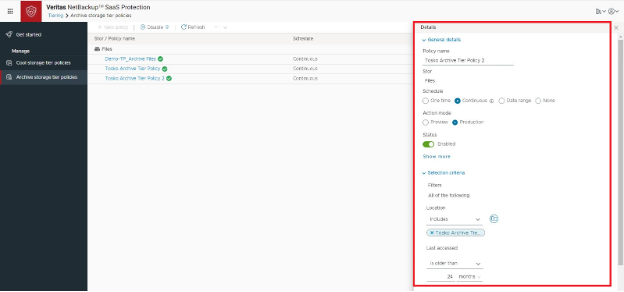
Figure 3: Creating a tiering policy in Veritas Alta SaaS Protection.
Veritas Alta SaaS Protection defaults to writing all data to either the Hot or Cool tier because, in the cloud, the solution runs things like full-text indexing, data classification, and integration with Azure Media Services and other analytics services which can involve opening files to render their contents. Therefore, writing data directly to the Archive tier in Azure could cause higher costs since other rules may run shortly after that wanting to open the files. Since the Archive tier involves higher activity costs for retrieval, especially early rehydration, writing all data to Hot or Cool first allows time for content analysis, PII detection, and keyword indexing processes to run before storage tiering rules come into effect.
Veritas Alta SaaS Protection’s cost-optimization approach for in-cloud tiering also means that data in the Archive tier can be fully searchable. This way, not only do we minimize activity costs, but the data in the Archive tier is readily searchable through the index. Rehydration of the data from the Archive tier only occurs if a user needs to read or export the file.
Search and the Archive Tier
By default, a search cluster in Veritas Alta SaaS Protection will index all item-level metadata, folders, and access rights, thus making all data in the Archive tier readily searchable by metadata.
This basic level of indexing – available in the Enterprise edition – does not involve a file open request to render the contents of files. Thus, it does not require a scaled search cluster configuration and needs very little storage space to maintain the index. As a result, the default indexing in the solution is fast, highly-scalable, very inexpensive, and delivers a cold archive that is searchable.
If you wish to use Veritas Alta SaaS Protection’s full-text search, and data classification – available in the Enterprise Plus edition – then the solution’s in-cloud storage tiering design will help by having these content-level processes work with the data while it is on the Hot tier. If data is content-indexed or otherwise classified and later moved to the Archive tier, then the data in cold storage will be fully searchable since the contextual data is maintained separately.
Cloud Data Management and the Archive Tier
Just as important as search is the ability to holistically understand the data you are storing, and the ability to manage it as needed.
For example, a legal situation may arise that requires particular data to be placed on litigation hold. Alternatively, a request under the GDPR may come in that needs you to isolate and delete files with an automatic audit record.
Traditionally, long-term retention, especially when handled with tape, is burdensome in this regard. It just is not possible to actively manage the data in long-term retention – you have to recall it to manage it.
Fortunately, that is no longer the case with the cloud. Regardless of the tier (Hot, Cool, or Archive), we can actively manage it in Veritas Alta SaaS Protection. Things like litigation hold, associating content with a legal case, classifying the data, storage cost analysis, retention, and search work with the data regardless of the tier.
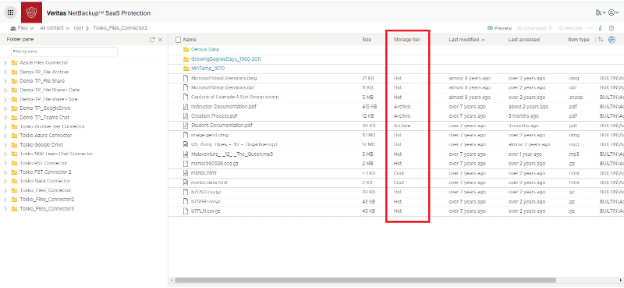
Figure 4: Content listing showing the cloud tiers used.
User Experience and the Archive Tier
Earlier we mentioned that information on the Archive tier is not instantly retrievable. It can take several hours to rehydrate.
In a recent presentation, we introduced the Archive tier to an IT team considering the cloud for long-term retention. In their scenario, it was essential to provide users with self-service access to the cloud archive. Veritas Alta SaaS Protection supports this in two ways
1. stubs in the on-premises file system
2. Web portal access with browse, search, recall, and share.
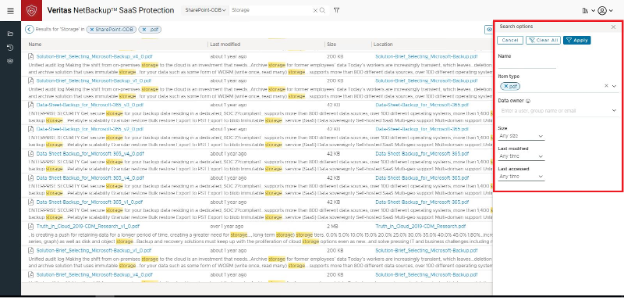
Figure 5: Results of a search of the word “storage” in all PDFs.
This particular organization felt that their user community would not take well to the Archive tier’s slow retrieval response. Even if the data is 20 years old, they explained, the expectation is that the file opens when requested.
In the screenshot above, we see in Veritas Alta SaaS Protection’s Web-access user portal that a search returns results across the tiers (items in the Archive tier have grey-colored file names). If the user clicks to open such a file, they see a pop-up that tells them it is now being rehydrated, and the item will be available within 15 hours.
If this user experience will not suffice for your user community, we recommend that your tiering policies in Veritas Alta SaaS Protection be used to phase data from Hot to Cool and should go no further than Cool. This way, you can still reduce your long-term cloud storage costs with the Cool tier, albeit to a lesser degree than with Archive, while supporting immediate access to all content for your users.
The good news is that you have total control over what tier your data resides, and whether or not end-user accessible data will be placed on the Archive tier.
Conclusion
Adoption of the Archive tier depends on your requirements, data management philosophy, and the workloads in question.
We believe the Archive tier is a perfect fit for closed project data, compliance data, legal discovery preservation, ex-employee records, culture preservation, and other such content that you need to keep but will not likely ever need to access again.
To learn more about Veritas Alta SaaS Protection and how your organization can optimize storage costs using the Archive tier, contact a Veritas account representative today!
