How InfoScale Can Assist Your Journey Into the Public Cloud

InfoScale is a market-leading software-defined application high availability solution designed to ensure that the technology resources your business relies on are highly available. InfoScale works with almost any hardware, software, and cloud service, and it provides several advanced features and capabilities that aren’t available natively. InfoScale helps maximize your investment by allowing you to run your business with the most cost-effective technology that provides the best experience for your end-users.
For example, an IT manager may be given the challenge of minimizing an infrastructure budget for an on-premises data center where maintenance costs are escalating. With InfoScale, IT managers have the flexibility to use public cloud services that may offer significant cost savings while providing the same level of service that your end-users expect.
A problem thus arises for the IT manager. How does one ensure that on-premises data is synchronized with data in the cloud?
The solution to this problem is InfoScale. As a software-defined solution, InfoScale allows data to be written to high-performance, scale-out storage infrastructure on-premises, which can then be seamlessly replicated to the public cloud.
Suppose you want to move data away from a particular cloud service. In that case, InfoScale can also replicate data back on-premises or on to any other public cloud, guaranteeing your right to move your data anywhere you want. InfoScale gives you the power to modernize or transform your datacenter in a way that best suits your business.
If there is ever any doubt that your infrastructure strategy (either private data center or public cloud) isn’t providing your organization with a satisfactory level of service, InfoScale will help you eliminate any gaps and smooth out the bumps in your digital transformation journey.
So what does this solution look like? Figure 1 will give you an idea of how it works.
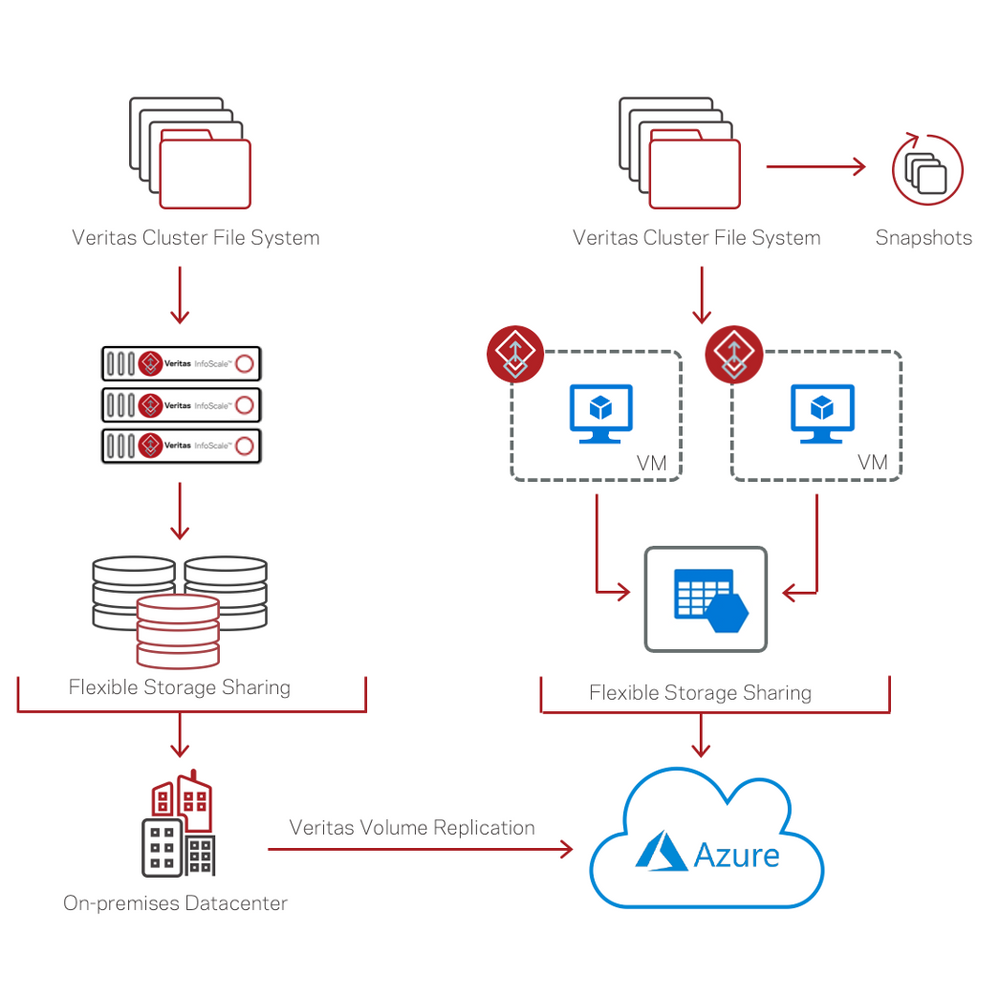
InfoScale is installed on-premises on your existing servers, creating a scale-out clustered storage platform (which also highly available and runs your applications). InfoScale can then replicate to a similar scale-out clustered storage platform built in the public cloud.
Here are the InfoScale components that make this work:
- Veritas Volume Replication – replicates your data
- Flexible Storage Sharing – shares local disk between nodes in the InfoScale cluster
- Veritas Cluster File System – a shared filesystem that enables all your cluster nodes to read and write data in parallel
- Snapshots – point in time images of the data in your file system
In Figure 1, your application can run simultaneously on each node in the InfoScale cluster using the (shared) cluster filesystem. The data written to the filesystem is replicated by Veritas Volume Replication to the cluster running in Azure.
Here’s a video that illustrates how this works.
The Azure cluster is built using Azure VM’s, and InfoScale is installed in the Azure VM’s to provide high-performance clustered storage and high availability for your application.
You can access the replicated data by running a failover in your on-premises site, using your Azure cluster as the failover target, or creating a snapshot of the data you can use for multiple purposes.
Veritas Volume Replication’s value is that it can make your data available anywhere regardless of the underlying infrastructure. VVR makes it possible to replicate data to and from nearly any cloud platform. Coupled with InfoScale’s availability orchestration and automation, applications and data can be made highly available while minimizing costs.
For more information about InfoScale, please take a look at our technical library.